
Entropy, Gini Impurity and Information Gain
Let us take the play tennis dataset and understand how a decision tree is constructed.
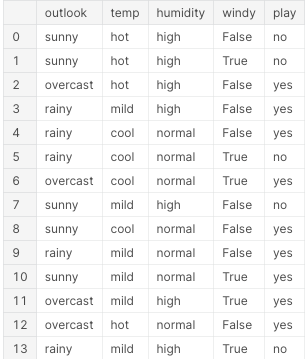 Figure-(1)
Figure-(1)
In the tennis dataset, we are given input features of weather conditions like outlook, temperature, humidity and windy based on which we have to predict the output of whether a person is going to play.
Let us consider for the time being that the root node is Outlook and based on which we are splitting the tree.
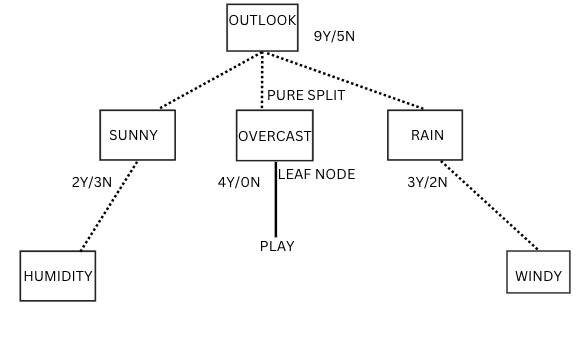 Figure-(2)
Figure-(2)
In outlook- we have 9Yes/5No for output play and after splitting based on the feature outlook, we have sunny-2Y/3N, overcast-4Y/0N and rain-3Y/2N.
Looking carefully at the decision tree, we can see that the overcast is a leaf node since it has a class of only 4Y and 0 no’s, which tells us that a person will definitely play whenever the outlook is overcast. It is a case of pure split. Since we have arrived at a pure leaf node, we won’t further split the tree from this node overcast.
If we look at sunny and rain, it is not a leaf node since it contains data of both the yes and no classes. Hence, we will again split from these nodes taking features like temp, humidity and windy until we arrive at the leaf nodes.
In this way, a decision tree is constructed. Let us understand the definition of entropy and Gini impurity and see how the purity of split is calculated mathematically. We will also look at how a particular feature is selected for splitting by using information gain mathematically.
Purity of split
- Entropy: Entropy is defined as the randomness or uncertainty in the data. It is a metric that measures the impurity.
- Gini-Impurity: Gini impurity is also a measure of impurity in a decision tree node.
Entropy=H(S), S=Sample.
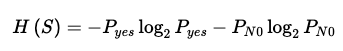 Figure-(3)
Figure-(3)
Where:
= Probability of output=1 =P robability of output=0
Gini Impurity (GI)
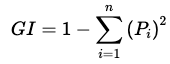 Figure-(4)
Figure-(4)
Where: = and for a binary classification problem.
Hence,
GI=1- 2 + 2
Let us take the example of the fruit dataset and understand the concepts.
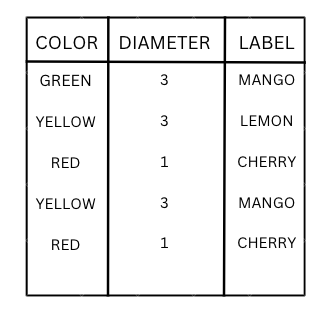 Figure-(5)
Figure-(5)
On creating a decision tree for the above data:
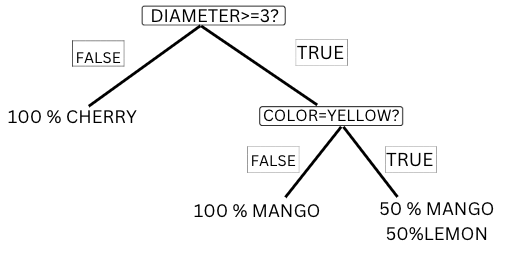 Figure-(6)
Figure-(6)
In the above fruit dataset, we have created a decision tree and can see that the decision node Is color==Yellow? Has 3+3 Mangoes and 3 Lemons.
The nodes after splitting the above decision nodes have two nodes:
-
Left node- 3Mangoes (Green color) is a leaf node and is the case of a pure split.
The entropy & gini-impurity for the left node will be
H(S)= -3/3 LOG2(3/3)- 0/3 LOG2(0/3) = 0
GI=1- 2 + 2 = 1 - (12 + 02) = 0
The entropy for the pure split is 0 meaning the split is having no/zero randomness or uncertainty in the data. It is justified as the split is having only the class of ‘mango’. The Gini-impurity for the pure split is also 0.
-
Right node- 3mangoes and 3 lemons is the case of an impure split. The entropy for the right node will be
H(S)= -3/6 LOG2(3/6) - 3/6 LOG2(3/6) = 1
GI=1- 2 + 2 = 1- (0.52 + 0.52) = 0.5
The entropy for the impure split is 1 meaning the split is having maximum randomness or uncertainty in the data. It is justified as the split is having 50% mango and 50% lemon. The Gini-impurity for the impure split is 0.5.
Hence, we looked at how the metrics entropy and gini-impurity assist in determining a split's purity(impurity), which answers our question of how to split a node in a decision-tree algorithm. We split the nodes in a decision tree such that the resultant splits have minimum impurity. Although both are used as impurity metrics, the basic difference between entropy and GI is that entropy ranges from 0 to 1 (0<=H(S)<=1) and GI ranges from 0 to 0.5(0<=G.I<=0.5).
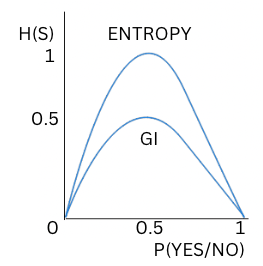 Figure-(7)
Figure-(7)
Feature Selection
- Information Gain: Information gain is defined as the information/knowledge gained after splitting the data based on a specific feature/attribute. It helps the decision tree decide which is the best feature to be used for splitting the data, reducing the entropy and increasing the information gain.
Information gain = Entropy(s) – [(average weight) * Entropy(each feature)]
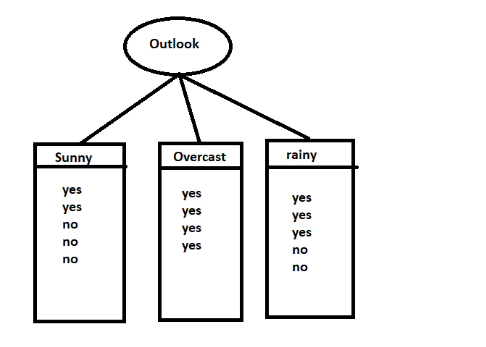 Figure-(8)
Figure-(8)
Let us look at the tennis dataset. Initially, we used the feature ‘outlook’ as the root node for splitting the dataset.
we have sunny-2Y/3N, overcast-4Y/0N and rain-3Y/2N.
E(Outlook)=-5/14 log (5/14)-9/14 log(9/14)=0.94
E(Outlook=sunny)=-2/5 log2/5 – 3/5 log3/5 = 0.971. E(Outlook=overcast)= -1 log1- 0 =0. E(Outlook=rainy)=- 3/5 log3/5 -2/5 log2/5 =0.971.
P(Sunny in outlook)=5/14 P(Overcast in outlook)=4/14 P(Rain in outlook)=5/14
Information from Outlook
I(Outlook)=(Probability * Entropy) of each category in feature ‘Outlook’ i.e. Sunny, overcast and rainy.
Information gained from Outlook,
IG(Outlook) = E(Outlook) -I(Outlook) =0.94 – 0.693 =0.247 So Information gain for Outlook is 0.247.
Similarly, after constructing the decision tree by selecting root node as another feature temperature, humidity and windy and thereafter calculating the information gain we get:- Information Gain(Temperature) = 0.029 Information Gain(Humidity) = 0.152 Information Gain(Windy) = 0.048
Conclusion
We can see that the information gained from Outlook is maximum and hence it will be considered as root node for splitting the tennis dataset.
Information gain helps us answer the question of which feature to select first and which feature to select next for splitting. We will select the feature that has the highest information gain and then split the node based on that feature.
Together these concepts of Entropy, Gini-impurity and Information gain help us in understanding the construction of a decision tree.
You can refer to my hands-on and project section in my blog. We will be implementing decision tree model for the ‘Tennis dataset’ using Python where you can see Entropy, information gain, Gini impurity for every node and practical implementation of a decision tree.