
What is Boosting?
Boosting is an ensemble of weak machine-learning models (Decision Trees) sequentially connected to obtain a single strong predictive model.
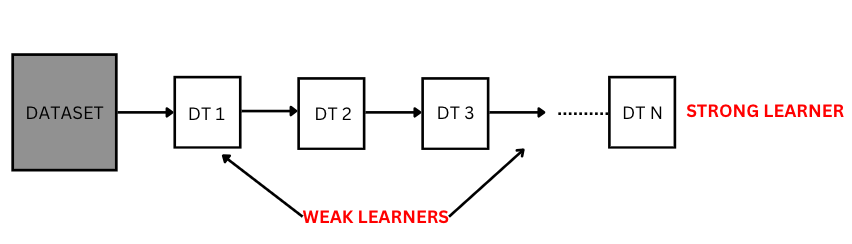 DT=Decision Tree.
DT=Decision Tree.
Importance of Boosting
A weak learner is usually a single decision tree model with low prediction accuracy, prone to overfitting and lacking generalization for the data.
Boosting combines multiple weak learners (DTs) serially to obtain a single strong learning model that achieves higher prediction accuracy and is generalized for the dataset.
For example, in a KBC contest, when a person in the hot seat seeks expert advice, multiple experts offer their opinions in their respective areas of expertise, leading to a strong conclusion.
Working of Boosting Algorithm
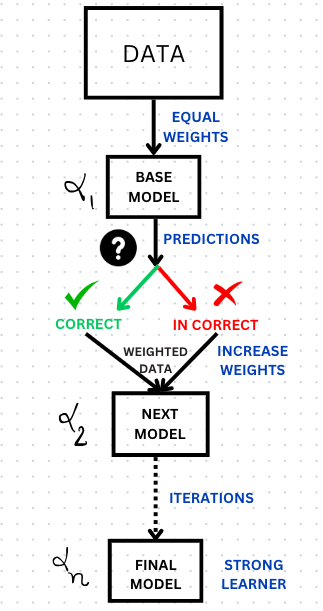
STEP 1:
In the boosting algorithm, we initialize the dataset by assigning equal weight to each data sample. This weighted data is then fed as input to the first weak learner model, also known as the base model, which predicts the outcome for all samples.
STEP 2: The boosting algorithm evaluates these predictions and increases the weight of the samples with incorrect predictions, and this weighted data progresses to the next serially connected weak learner. The algorithm also assigns a confidence/weight to the weak learners based on their performance granting more influence on models with accurate predictions.
STEP 3:
STEP 1 and 2 are repeated until the training error falls below a desired threshold.
Finally, it combines the outputs from weak learners and constructs a strong learner, ultimately enhancing the predictive capability of the model.
Roughly speaking, the equation for boosting will be
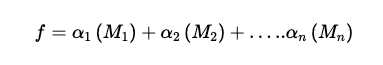 α i=weights/confidence of the ith model.
α i=weights/confidence of the ith model.
α signifies how confident a model is in its prediction.
The higher the α of a model, the greater its influence on the final decision.
Bagging VS Boosting
| BAGGING | BOOSTING |
|---|---|
| Aims to reduce variance. | Aims to reduce bias. |
| Base learners are trained parallelly and are independent with equal weights. | Base learners are trained sequentially with varying weights. |
| Minimizes error by aggregating predictions through averaging or majority vote. | Emphasizes incorrectly classified data from the previous model. |
| Less susceptible to overfitting. | May overfit training data if not carefully controlled. |
| Example:Random Forest. | Example:AdaBoost and Gradient Boosting |
Challenges in Boosting
- The iterative nature of boosting makes the algorithm sensitive to outliers.
- Careful preprocessing of data is crucial to reduce the influence of outliers.
- Real-time implementation of the algorithm is challenging due to its complexity.
- Boosting algorithms are computationally expensive, making them less suitable for large datasets.