
K-Nearest Neighbors
Introduction:
Machine learning can be a complex field, but there are some algorithms that offer a simple and straightforward approach to problem-solving. One such algorithm is K-Nearest Neighbors (KNN). In this blog post, we will decode the concept of KNN in simple terms, understanding how it works and its practical applications.
What is K-Nearest Neighbors (KNN)?
Imagine you have a group of friends, and you're trying to figure out if a new person is more likely to be your friend or not. One way to make a prediction is by observing their characteristics and comparing them to your existing friends. KNN works on a similar principle.
K-Nearest Neighbors is a simple supervised machine-learning algorithm used for both classification and regression problems. However, it’s mainly used for classification problems. K in "KNN" refers to the number of nearest neighbours that will be used for classifying the new data points. KNN predicts the class or value of a new data point by considering the similarity of the "K-nearest neighbours" in the training dataset.
‘KNN is a non-parametric and lazy-learning algorithm’.
KNN is a non-parametric method since it doesn’t make any assumptions about the underlying data distribution. It is called a lazy-learning algorithm because it doesn't have a training phase and instead relies on storing the entire training dataset. During prediction, it compares the new instance with stored instances to determine nearest neighbours and make predictions.
How does KNN algorithm work?
As previously stated, the KNN algorithm is primarily used as a classifier. Let's take a look at how KNN works with the help of an example.
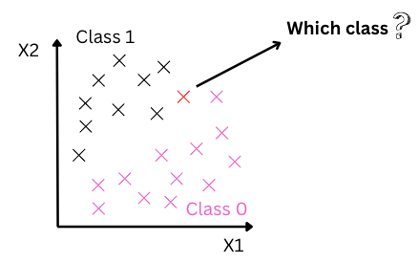
We have data points with 2 features-X1, X2 and corresponding labels as
class 0(Pink data points) or class 1(Black data points). With the help of KNN, we will classify the new test data point(red data point) as either 0 or 1.
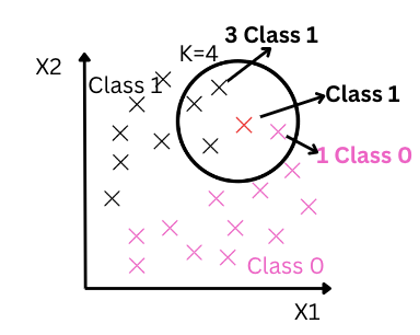
Let’s consider K=4.KNN will calculate the distance between the new test data point and all the other training points. It will then select the K=4 Nearest Neighbours or we can say it will choose 4 training data points that are nearest to the test data point.
Next, it checks the class of each neighbour and assigns the class that has the majority among the neighbours to the new data point. Since 3 nearest neighbours belong to class 1 and 1 neighbour belongs to class 0, this new data point will be assigned to class 1.
Steps in K-Nearest-Neighbours:
- Collect and organize a dataset consisting of labelled examples, where each example has features and a corresponding class or value.
- Determine the value of hyperparameter ‘K’(nearest neighbours) that has the minimum error rate.
- Find the K-Nearest Neighbours of the new data point using distance metrics like ‘Euclidean’(commonly used), ‘Manhattan’, ‘Hamming’ etc.
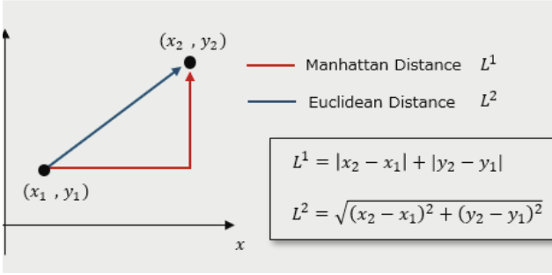
- For classification, count the neighbours belonging to each class and assign the class with the most votes among the K nearest neighbours. For regression, calculate the average value of the K nearest neighbours.
- Assign the majority class or average value as the predicted class or value for the new data point.
That's it! The KNN algorithm is as simple as that. It's like asking your neighbours for advice based on how similar they are to a new situation.
Advantages:
- It's simple to implement and easy to understand.
- It has vast applications in various domains such as image recognition, recommendation systems, and medical diagnosis.
- It’s ideal for non-linear data since it’s a non-parametric algorithm.
- It can be used for both classification and regression problems.
Disadvantages:
- Being lazy, it requires high memory for storing large training datasets.
- Computationally expensive because of calculating the distance between the data points for all the training samples.
- Need to determine an appropriate value for the "k" parameter as the wrong choice can give inaccurate predictions.
- It’s sensitive to irrelevant features and proper feature selection is needed.
Conclusion:
In conclusion, the K-Nearest Neighbours (KNN) algorithm offers a simple yet powerful approach to machine learning tasks. By considering the similarity between data points and their neighbours, KNN can make accurate predictions and finds applications in various fields of data analysis and decision-making.
In the hands-on project section, we will implement KNN using Python and learn how to determine the value of the hyperparameter 'K' .